
Introduction
Online book reviewing platforms are a rich source of information for studying various aspects of reading, writing and other book-related behaviour (Rebora et al.). Reviews may be investigated in literacy studies, they give access to the reader’s experience, but may also be informative of wider social issues such as social inequality (D. L. Miller; Driscoll and Rehberg Sedo; Dörrich). Reviews can be investigated to throw light on the books that they discuss and to learn about influence on the book market (Harris; Sutton and Paulfeuerborn). In this article we will use tools of corpus linguistics to look at various aspects of evaluation of literature as practised on online book reviewing platforms.
We will first give an account of the book reviewing sites and the reviews that their visitors write. Then we will introduce our corpus-based methodology, specifically Sketch Engine, a toolset developed originally for lexicographical research, and describe the data that we will use in the rest of the article. Then we will carry out a number of exploratory investigations to see what corpus approaches can teach us about reader response to literature and about reading more generally.
Many researchers have approached online book reviews as an alternative form of the newspaper literary review (Salgaro and Rebora; Bachmann-Stein and Stein; Neuhaus). It is true that to some extent both types of review fulfil the function of telling prospective readers what to expect from a given book. However, for us the value of the review is especially in what it can show us about readers’ reading experiences and book evaluations. According to Alison Hegel, ‘[…] reviews are a rich source of first-hand insight into modern readers’ expectations for and reactions to books,’ (4-5) and Martin Rehfeldt writes ‘Lay reviews should not be seen as degenerate professional criticism […], but as documents of reception and as potential objects for research […]’ (286).[1] We briefly discuss some limitations of using reviews for this purpose in the next section.
Some words must be said about the role of Sketch Engine in the preparation of this article. While there are many researchers who flock into Digital Humanities who have no coding skills themselves, there is an important school that believes that the intellectual benefits of computing only come to those who are code-literate.[2] And there is a strong belief in the DH community that the software that we write and use should be available as open source. By contrast, this paper uses a closed source lexicographical corpus workbench, Sketch Engine. This was a pragmatic choice.[3] It was selected for being interactive, user-friendly, and suited to the task, a choice further motivated by the resources available to the project. Usage of expert tools such as Sketch Engine should of course never be uncritical.[4]
Book reviewing platforms
There is a wide variety of online platforms where people discuss books (Boot, “Genre Analysis”). These include book sellers’ sites such as Amazon, general purpose social media such as Facebook, YouTube, Instagram, Twitter and Tiktok, as well as weblogs and specialized web platforms such as Goodreads (Vlieghe et al.; Albrecht; Jaakkola; Gruzd and Rehberg Sedo; Driscoll). In this paper, we are interested only in platforms where visitors can leave reviews of books. We define a review as a usually evaluative textual response to a book, mostly from a personal perspective, that may range in length from a few words to a few hundred words or more. Platforms where people write reviews include the booksellers’ sites and the specialized web platforms.
While the booksellers’ sites generally do not offer the reviewers additional ways to interact with other readers, the specialized websites offer ways to make friends, to comment on posts, to have forum-based discussions as well as other interactive functionality, to the extent that sites such as Goodreads have been described as book-based social networking sites or as book communities (Thelwall and Kousha; Lukoschek, Katharina). I will describe the Goodreads-like sites as book-based ‘affinity spaces’, using the term coined by education scientist Gee to avoid the assumption of ‘belonging’ inherent in the word ‘community’ (Gee, Situated Language). Affinity spaces are ‘loosely organized social and cultural settings in which the work of teaching tends to be shared by many people, in many locations, who are connected by a shared interest or passion’ (Gee, “Affinity Spaces”). The booksellers’ sites and the book affinity spaces also differ in demographics: while Amazon book reviewers are (as far as known) mostly male and over 50, participants on book affinity spaces are mostly young and female (Pinch and Kesler; Jessen). On both platform types most participants are well-educated.
Some research has been done on differences between reviews from the overtly commercial booksellers’ sites and the non- or tacitly commercial book affinity spaces (Newell et al.). Reviews on commercial platforms are generally shorter (but not all studies agree), they use more vocabulary related to the act of buying, they devote less attention to the content, style and author of a book. However, since the mentioned studies vary in their design, with only two comparing the same pair of sites, it is hard to draw generalizable conclusions from their findings.
Some researchers have questioned the value of online reviews because the platforms are usually owned by ‘big tech’. Already in 2013 Nakamura wrote of Goodreads that ‘open access to a for-profit site like Goodreads has always exacted a price—loss of privacy, friction-free broadcasting of our personal information, the placing of user content in the service of commerce, and the operationalization and commodification of reading as an algocratic practice’ (9). I believe this is an overly pessimistic view, which underestimates the agency and autonomy of readers who freely choose to use the site for their own purposes. That for Amazon a book is a commodity does not ‘commodify’ reading. A term like ‘algocratic’ is demagogic, fostering the idea that there is something inherently sinister about algorithms. More recently, Simone Murray wrote an essay about Goodreads and book history which seems to assume that if our reviews are useful to Amazon, that must necessarily be an evil thing, leading to ‘enmeshing books in a world of vast profits, corporate IP and data-mining’ (983; see also Walsh and Antoniak). For many researchers it is apparently hard to accept that a company such as Amazon, with all its ruthlessness towards its employees and competitors, can still maintain a site that is a reader’s delight and a useful resource for the scholar at the same time.
That we must be aware, when using data in research, how the data came about, is evident, and the black box character of the platforms’ algorithms can make that difficult. The platforms’ commercialism, however, is certainly not the only influence on the evaluative content of the reviews. Book reviews, as all activity on social media, are also a performance of self. Book reviewing platforms can be seen as ‘exhibition spaces where individuals submit artifacts [=the reviews] to show each other’ (Hogan 377). Jaakkola writes about the objective of ‘creat[ing] a public image of oneself as a reading person’ that can influence book reviews, and self-presentation is an important motive for blogging (Tian). While book reviewing research so far only limited attention was devoted to this phenomenon, we should clearly be alert to it.
Methodology: Corpus approaches
Use of the term ‘corpus’ in this context derives from its use in corpus linguistics. McEnery and Hardie define a corpus informally as ‘some set of machine-readable texts which is deemed an appropriate basis on which to study a specific set of research questions.’ In linguistics, a corpus approach bases itself on the study of (large rather than small) collections of observed language data, rather than on the researcher’s intuitions on what constitutes correct or appropriate language. Corpora and corpus linguistic tools are increasingly used outside of the linguistic community, as is the case in this paper (Goźdź-Roszkowski and Hunston). The tools used in corpus approaches include the analysis of frequency lists, possibly limited to certain types of words, key words (words that occur significantly more in one corpus than in a reference corpus), collocations and concordances (Jaworska). There is no reason, however, why corpus approaches should be limited to these ‘canonical’ tools. A distinction is sometimes made between corpus-based and corpus-driven approaches (Tognini-Bonelli). In the former approach, corpora are used to study predefined, theoretical linguistical features. The latter approach is inductive ‘so that the linguistic constructs themselves emerge from analysis of a corpus’ (Biber). In our analysis of book reviews, we limit ourselves to a number of corpus-based explorations.
The specific corpus tool that we will use is Sketch Engine (Kilgarriff et al.). Sketch Engine is a popular corpus analysis toolset developed principally for lexicographical research. Its main component is the word sketch, a tool for collocation analysis (Kilgarriff and Tugwell). Rather than working on the basis of frequencies of adjacent or near-adjacent words alone, word sketches take into account the grammatical relations that can exist between words. For a verb, word sketches can be used to display words that occur as subject or as object of the verb. For all word classes, word sketches can show words that are used to qualify the target word, that occur in ‘and/or’ constructions with the target word, etc. The candidate collocations are selected on the basis of a ‘sketch grammar’, a set of regular expressions over the sentences’ POS-tags. It can display these collocations ordered by salience. This makes Sketch Engine a useful tool for investigating what are the contexts in which, in a certain corpus, words are used.[5] It is also possible to create word sketch differences, a display of the difference in behaviour of two words in the same contexts. This tool can also be used to compare the behaviour of a single word in two different subcorpora.
Beyond the word sketch, Sketch Engine has other tools that one would expect of a corpus analysis toolset, such as support for metadata at the document level and support for CQL (Corpus Query Language), as well as tools that are specifically useful in a lexicographical context, such as automatic dictionary drafting. Beyond its home base in lexicography, Sketch Engine is also beginning to be used in wider Digital Humanities contexts (Moreton; Mpouli and Ganascia).
Data
To examine the possibilities of Sketch Engine for investigating reviews, we use two corpora. The first corpus that we use is in English and contains N= 373,854 reviews taken from Amazon (52%) and Goodreads (48%). We selected reviews from existing corpora (Ni et al.; Wan et al.). The corpus contains two subcorpora defined by rating (four or higher and three or lower). The second corpus contains N= 200,410 Dutch-language reviews taken from the Online Dutch Book Response (ODBR) corpus (Boot, “Online Book Response”). About half of them come from bol.com, The Netherlands’ largest online bookseller. The other half comes from various online book reviewing sites, comparable to Goodreads. The ODBR corpus as uploaded into Sketch Engine has subcorpora defined by rating as well as by genre. The genre subcorpora include one containing only reviews of suspense novels (including the so-called ‘literary thriller’) and one containing only reviews of (general) literature. The genre is assigned by the publisher.
When ingesting the data, Sketch Engine does lemmatisation and part-of-speech tagging. While no systematic evaluation of pre-processing quality was performed, repeated inspection suggests wrongly labelled words to be very infrequent, both for English and for Dutch.
As we saw above, both the demographics of the reviewers and properties of the reviews depend on the site type. Our corpora therefore include about equal quantities of reviews from overtly commercial (bookseller) sites and from reader-oriented sites where commercial interest is usually more tacit.
Aspects of evaluation
What follows are four exploratory investigations. In each of them, we very briefly discuss the theoretical relevance of the topic that we investigate and formulate some questions. Then we will use one or more of the tools available within Sketch Engine in an attempt to answer these questions; in a concluding paragraph, we will summarize our preliminary findings both with respect to the questions we formulated and with respect to what Sketch Engine can do. To be clear, none of the investigations pretends to provide final answers to the questions we discuss: their purpose lies in showing what is possible with review data utilizing an off-the-shelf corpus tool as much as in the initial answers we find.
It is important to note that not all readers are reviewers. Even on the reviewing sites, the reviewers are in a minority compared to those who use the platforms to find information or just to track their reading (Jessen). As far as I am aware, there exists no research comparing reviewing and non-reviewing readers with respect to their reading behaviour. It is likely that those who write longer reviews, being forced to put their thoughts into words, will have more explicit opinions. They are probably also those who are comfortable with revealing personal data (Blank and Reisdorf). Studies that explicitly compare the reading behaviour of these two groups are sorely needed.
Exploring the alleged inanity of online reviews: plot
In their classic introduction into literary evaluation, Von Heydebrand and Winko write disapprovingly of ordinary readers who ‘usually bring their own needs and values to or into the work regardless of the text’s intention’ (186), and summarily write about a reader’s ‘heteronomous and therefore inadequate reading’ (213). Following this traditional suspicion of lay readings harboured by literary scholarship the prejudice against lay reviews (for examples see Stein; Ernst) has been widely shared. According to Bachmann-Stein, ‘Lay reviews do not orient themselves towards the standards of literary criticism. Rather, the reviewing is guided by psychological criteria referring to the impact of the individual reading experience’ (89). This distrust of online book discussion went into overdrive in Ronán McDonald’s pamphlet on The death of the critic. He saw it as a form of ‘people power’ that ‘decks out banality and uniformity in the guise of democracy and improvement’ (17).
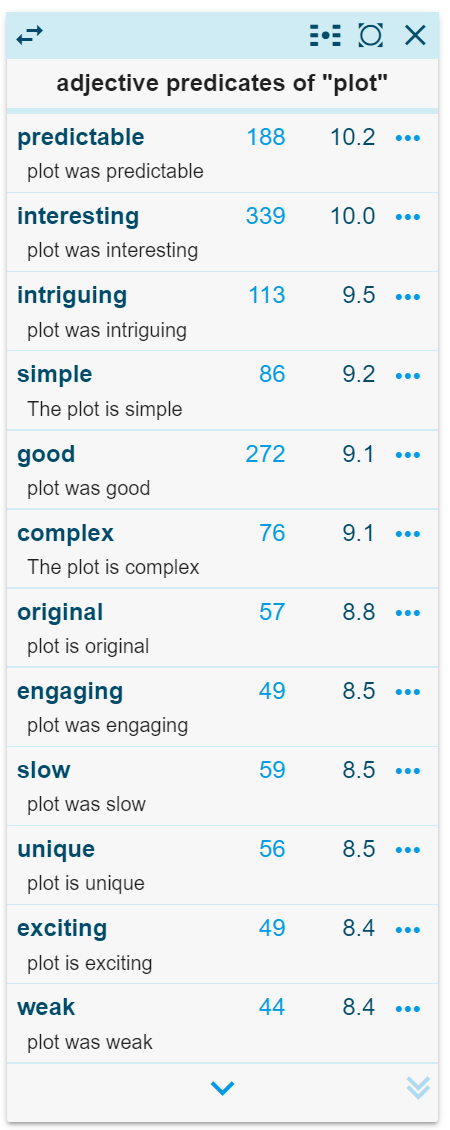
To check whether this widely held assumption that reader reviews talk mostly about the reading experience is true, we will look at a word sketch of ‘plot’ (but might as well have discussed the writing, or the dialogues, or other issues – see below). Story or plot is a central concern in literary studies and a well-crafted plot is important for readers of all types of narrative (Boyd; Tobin). In online book reviews, the plot is one of the most frequently discussed aspects of the book (Kutzner). This is true for literary as well as for popular books (Daniels). What does a word sketch of ‘plot’ show us about how it is discussed? If the reviews are mostly about the readers’ experiences, we would expect the collocates of ‘plot’ to refer more often to the readers’ impressions, and in general to avoid technical discussion of books’ merits.
As explained above, a word sketch displays the collocates of ‘plot’ in several contexts (‘grammatical relations’, in Sketch Engine terminology). Figure 1 shows how Sketch Engine presents the adjectives most frequently associated with the word ‘plot’ in the Goodreads corpus,[6] followed by the absolute frequency of the collocation and its (LogDice) typicality.[7] These are words such as ‘predictable’, ‘interesting’ or ‘intriguing’ that we would indeed expect to be used with ‘plot’. Table 1 gives the full list of these adjectives. Some are mostly evaluative (‘excellent’, ‘awesome’, ‘bad’), some are mostly descriptive (‘twisty’, ‘straightforward’), others are evaluative as well as descriptive (‘predictable’, ‘compelling’, ‘confusing’). Many of the words do indeed imply a reading experience (‘intriguing’, ‘engaging’, ‘compelling’), and are necessarily subjective. But taken together, they provide a rich and balanced vocabulary for qualifying plots.

Table 2 presents nouns modified by ‘plot’ in the reviews. Some are compounds denoting aspects of plots in the books (‘plot twists’, ‘plot devices’, ‘plot direction’), some are about the discussion of plot (‘plot summary’). The algorithm is clearly imperfect: ‘plot nothing’ does not seem to make sense. Yet it is impressive that simple statistics and a few language rules can lift these patterns out of a few hundred thousand reviews. It is relevant because it shows that, at least collectively, online reviewers have a subtle and extensive vocabulary to talk about plot, even if individually they don’t use all these collocations. If they were only interested in ‘their own needs and values’ there would be no need for this extensive vocabulary. This does not imply that the majority of reviews should discuss the plot – for one thing, most reviews are too short for that.
Plot is certainly not the only aspect of books that reviewers discuss. This is shown by another entry in the ‘plot’ word sketch, the ‘Plot and/or ….’ list. Table 3 shows an edited version (there were too many irrelevant words here). These words are used by reviewers in a conjunction with ‘plot’, so they write ‘plot and writing’, ‘plot or theme’, etc. The words in this list show that online reviewers are not merely interested in plot. We could look at the Work Sketch for each of these terms and find a similarly nuanced vocabulary for discussing that aspect. For reasons of space, we can’t go into these words’ collocations, but taken together, these examples suggest that online book reviewing practices are certainly not simplistic – they are not merely based on feeling and identification – but display solid discussion on a variety of aspects related to the merits of books.[8] The corpus analysis tool allows us to perceive that by zooming out and looking at the patterns that emerge when we look at thousands of reviews collectively.
Exploring what constitutes ‘beauty’ in reading
Let us move from the noun ‘plot’ to an adjective, ‘beautiful’. According to an empirical study by Knoop et al., ‘beautiful’ (or rather it’s German translation ‘schön’) is the adjective that is most frequently suggested to describe an aesthetic literary experience. What does the way it is used suggest about that experience? Table 4 shows the nouns modified by ‘beautiful’ in the Goodreads corpus.
As we see, the list contains many of the words that in a book review would be expected to be qualified as beautiful (‘writing’, ‘story’, ‘cover’). But the list also contains many words that do not refer to the book as a reviewed object, but to the story world (‘woman’, ‘city’, ‘gown’).[9] Some could be used in both ways (‘gift’, ‘drawing’). This presents us with a problem of ‘opinion target identification’ (Catharin and Feltrim).
Within the Sketch Engine context, there does not seem to be a way to differentiate the two domains. One option might be running a word sketch difference of the word ‘beautiful’ in subcorpora of positive and negative reviews. We could hypothesize that beautiful women occur in both high- and low-rated books, while beautiful writing probably occurs more in high-rated books. Then, in a word sketch difference of the word ‘beautiful’ between the high- and the low-rated reviews, the book domain collocates of ‘beautiful’ should appear on one end of the spectrum, the story-word collocates should be unmarked. But experiments show this doesn’t work. Beautiful scenery, beautiful cities and beautiful women occur more in positive reviews than in negative ones. Because it seems unlikely that books about beautiful scenery (or cities, or women) are rated more highly, the findings imply that in negative reviews, reviewers may see no reason to mention these aspects of the story world in their reviews. We will come back to this when we use a key word analysis to investigate differences between positive and negative reviews, below.
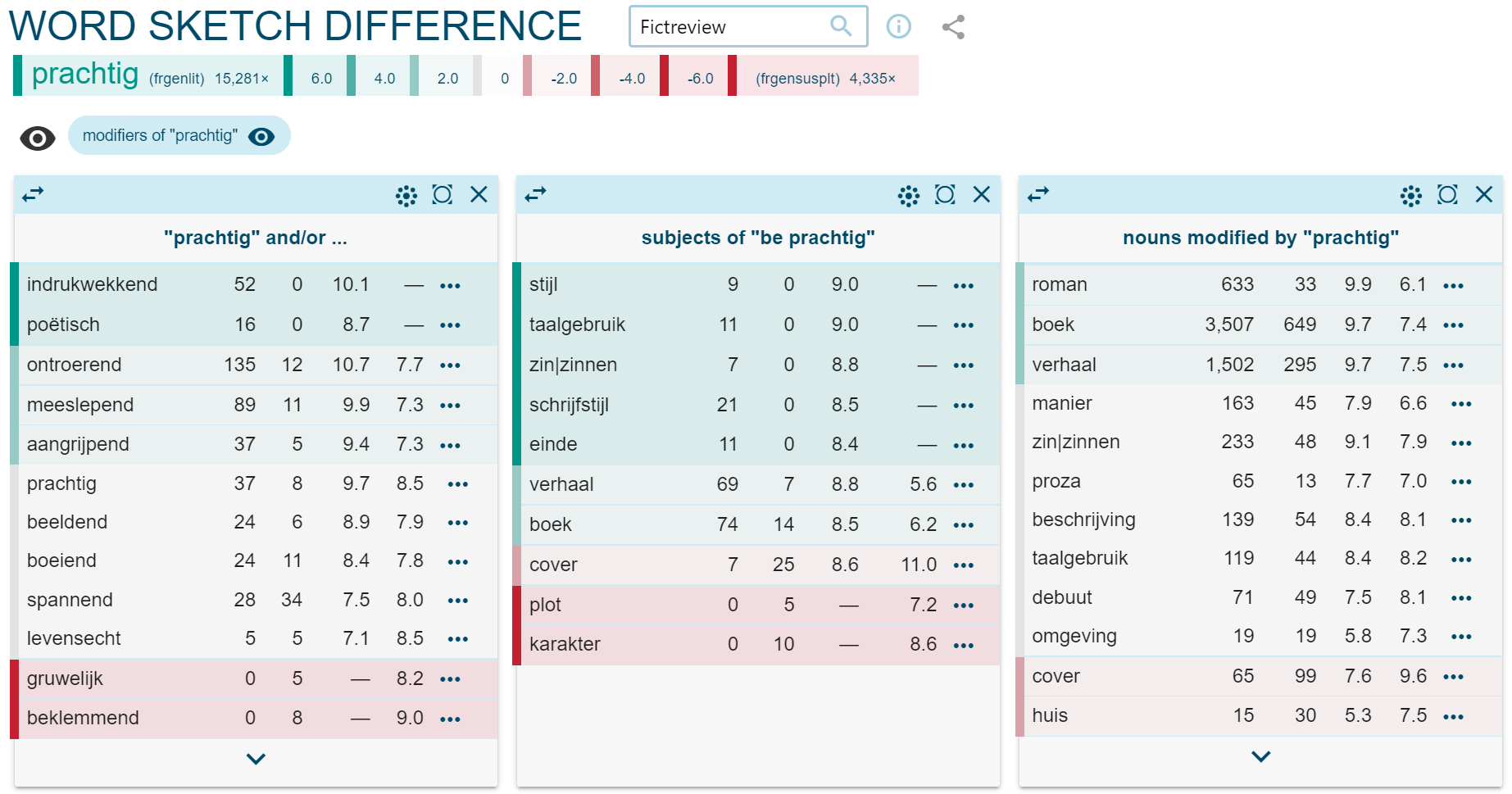
Of the collocates that do refer to reviewed aspects of the book, some refer to the linguistic aspects of the book, to the writing (‘writing’, ‘prose’, ‘language’), others refer to the story (‘story’, ‘ending’, ‘narrative’). If we assume with Jakobson that the poetic function is the essence of literary art, and distinguish distanced readers (who focus on form) from identifying readers (who focus on character and plot), it seems likely that the form-oriented words appear mostly with literary books, the story-oriented words with suspense-driven books. We can test that hypothesis by creating a word sketch difference by genre (Heydebrand and Winko). For that, we move to the Dutch corpus, as there we have subcorpora based on genre.[10] We create in Sketch Engine a word sketch difference for the Dutch word ‘prachtig’ (one possible translation of English ‘beautiful’) between the literary and the suspense subcorpus. Sketch Engine shows the output as displayed in Figure 2. The words in green occur typically in reviews about literary books, the words in red occur typically with suspense novels. The numbers after the words give the frequency and (LogDice) typicality in the respective subcorpora.

The strongest indications for differences in how ‘prachtig’ is used for evaluating the two genres, can be seen in the columns ‘“prachtig” and/or …’ and ‘subjects of “be prachtig”’. Table 5 gives the translations of the Dutch words in Figure 2. Except for ‘house’, all words come from the reviewing domain, not the domain of the story world. In the subjects-of column we see that what is described as beautiful in suspense reviews are character and plot[11] while in the literature reviews, the first four collocates refer to style. Still, the combination of ‘beautiful’ and ‘story’ also occurs more typically in literary reviews than in suspense reviews. Moving to the and/or column, we see that close associates of ‘beautiful’ in the suspense genre are ‘horrible’ and ‘oppressive’, words that are clearly connected to the effects of the story. In the literary reviews, ‘poetic’ and to a lesser extent ‘impressive’ seem clearly related to style; the other three words are all (near-synonyms of) ‘moving’. While stylistic aspects undoubtedly are partly responsible for a text being moving,[12] what moves us are the characters and what happens to them.
The modified-by column contributes further support to this discussion, ‘story’ again appearing as a collocate of ‘beautiful’ in the literary reviews, and ‘house’ as an element of the story world coming up in the suspense category, which might indicate that the setting of the story world be important to this type of reader. Summarizing, we could say that what suspense readers consider beautiful when evaluating a book are plot and character (and the cover); what literary readers consider beautiful is style and story. This seems to confirm the conclusion of Riddell and Van Dalen-Oskam that there is an overlap between distanced and identifying readers: distanced readers are identifying readers with more reading techniques at their disposal (with the corollary that all readers are identifying readers).
Exploring the role of the body in reading
That reading is an embodied activity is widely accepted among researchers:[13] ‘[P]eople imaginatively project themselves into text worlds via embodied simulations,’ writes Raymond Gibbs (222). If this is true, we should see a reflection of that in the review texts.
In this connection, it is interesting to look once more at the word sketch for ‘beautiful’. The top modifiers of beautiful (in LogDice order) are given in Table 6. While some of these modifiers are neutral, many have a clearly corporeal semantic component.[14] While for ‘heartbreakingly’ or ‘painfully’ the reference to bodily perceptions is quite explicit, we would like to suggest an embodied dimension also for ‘surprisingly’ and its stronger variants ‘amazingly’ and ‘stunningly’, for ‘hauntingly’ and others (C. R. Miller). It appears that bodily simulation in processing and understanding a fictional text, as described by Gibbs, transpires to the evaluation of that text.
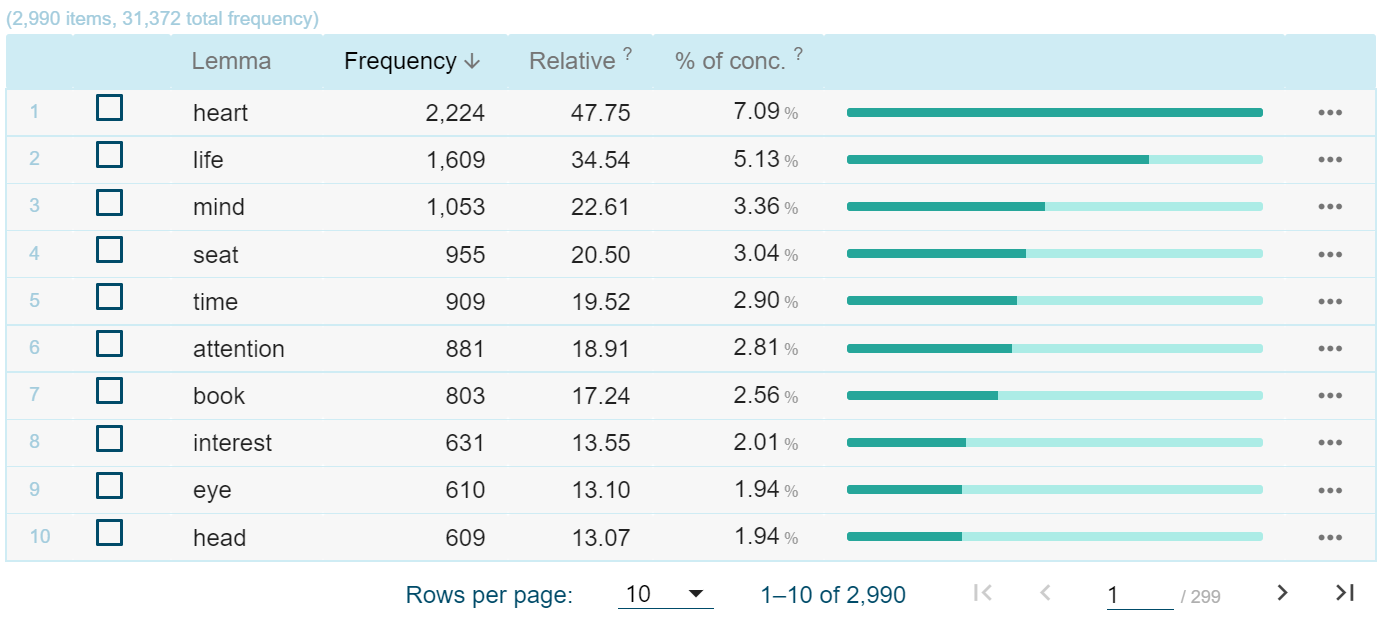
To look more systematically into the role of embodiment, we would like to search for references to body parts. While Sketch Engine does not know which words refer to body parts, we can find many examples of the body’s involvement in reading thanks to the fact that ‘you’ in book reviews usually refers to the reader. A search for ‘your’ followed by a noun brings up many relevant phrases. We can do this in Sketch Engine using the CQL option in the concordance tool, and then creating a frequency graph for the noun. The top results are shown in Figure 3. The most frequently occurring word in Figure 3 is ‘heart’. The context menu allows us to jump to a concordance of the phrase ‘your heart’. Then we find phrases from reviews such as ‘the book is going to break your heart (in the best way possible)’, ‘a great historical romance to warm your heart’, ‘deep moments, the ones that rip your heart out’, or ‘has your heart ever exploded with so much joy?’

Table 7 shows some verbs and expressions occurring with ‘your’ + body part. Some of these are literal expressions, others are metaphorical. That a book ‘brings a smile on your face’ or ‘tears to your eyes’, or that you ‘shake your head’ over a character’s action – all these are literal expressions about bodily response to reading. However, most of the expressions in Table 7 involve the body in a metaphorical sense. With Gibbs and Matlock we assume that people might ‘understand metaphors by creating an imaginative simulation of their bodies in action that mimics the events alluded to by the metaphor.’ Expressions stating that a book makes you ‘open your heart’, that it ‘blew off your head’, that it ‘hits you in the face’ or ‘gets under your skin’ evoke bodily metaphors for what reading does to the reader.
Thus, the role of the body in these expressions is in most cases distinct from the bodily involvement in comprehending and experiencing (metaphors in) fictional language, which is the focus of Gibbs. They are rather comparable to embodied metaphors used for the process of reading, such as ‘reading is a journey’ or ‘reading is eating’ (Nuttall and Harrison; Ross; Herrmann and Messerli). What we see here is another way in which the body is likely to be inextricably involved in reading, as documented by lexis referring to body parts and processes. It is interesting to note that almost all of these expressions are used to describe positive reading experiences.
Exploring differences between positive and negative reviews
Research into reading has often focussed on the good things that reading can result in: empathy, self-reflection, an interest in others (Koopman and Hakemulder). But not all reading experiences are positive and not all people like all books. We can distinguish the positive from the negative reviews on the basis of the accompanying rating (number of stars). But what are the textual differences between positive and negative reviews? It stands to reason that they can be distinguished based on positive and negatively valenced words.[15] But what other differences are there? Taboada and others look at words and constructions that can be used to convey negativity and illustrate those, among others, with quotes from movie and book reviews. Among the negative constructions they mention are rhetorical questions, sarcasm, certain suffixes (‘-let’), certain words (‘actually’), direct quotations, the juxtaposition of a very positive intensifier (such as ‘hilariously’) with a negative adjective (‘bad’), and why-questions. Crossley and others use LIWC[16] and their own sentiment analysis tool (SEANCE) to compare positive and negative reviews. They find that negative reviews use more negative emotions (particularly anger-related terms), negations, exclusion terms, spatial terms, understanding and certainty (as defined by SEANCE). Positive reviews use more positive emotion terms, social and certainty (as defined by LIWC) terms, as well as terms related to power and respect. They also note that certain POS-tags are useful for discriminating positive from negative reviews.
We will use a keyword analysis to investigate the characteristics of negative vs. positive reviews, complemented by a brief analysis using LIWC. Keyword (or keyness) analysis renders the statistically distinctive words of a focus corpus as compared with a reference corpus (Bondi and Scott). Rather than examining content, we will initially look at function words and POS-tags. We use our subcorpora defined by rating: a subcorpus pos, containing all reviews with rating four or five, and a subcorpus neg containing ratings one, two and three.[17] The reason for including three among the negative reviews is partly practical, as the distribution of ratings is heavily skewed towards the higher ratings. In the English corpus, the ratings 1 and 2 together account for less than 10 percent of the reviews, while the ratings 4 and 5 account for 74 percent. But that also means that a 3 represents a distinctly below-average reading experience. A book with rating 3 is typically described as ‘okay’ or ‘decent’, but generally still something of a disappointment.
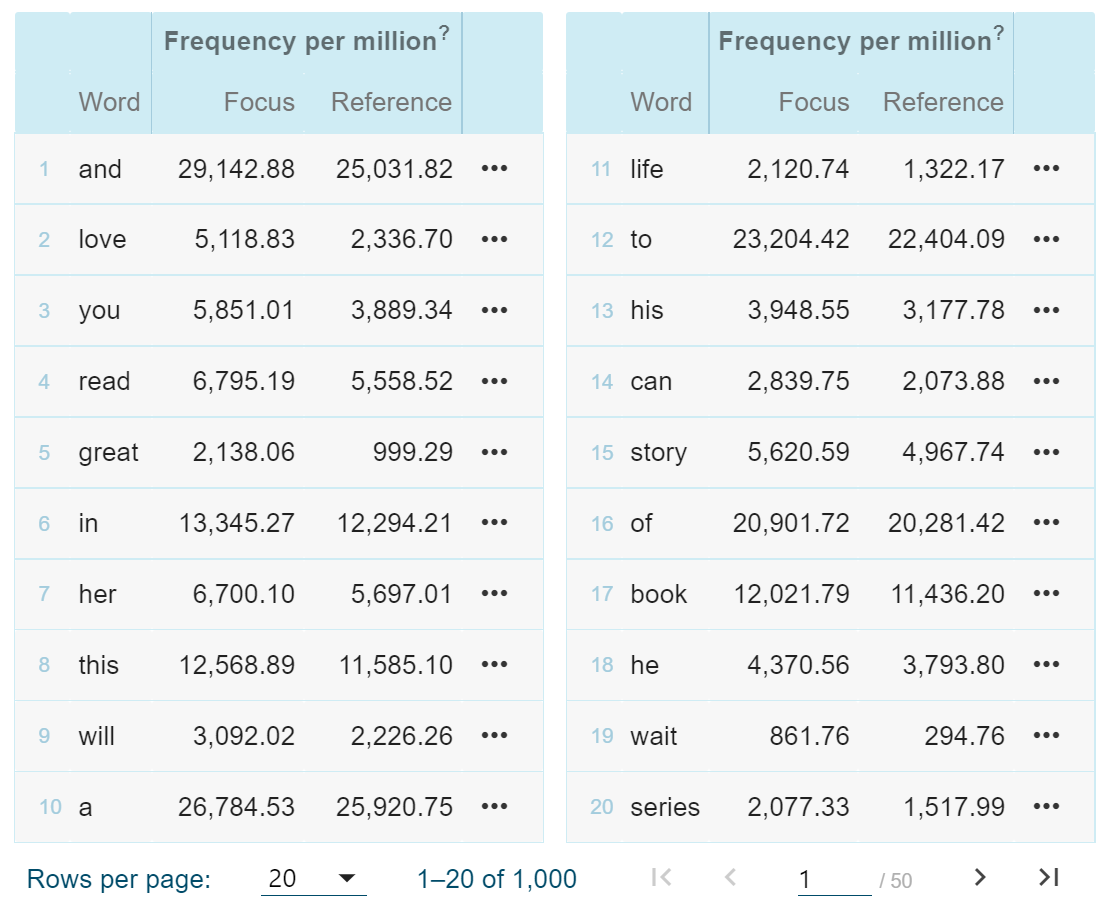
Figure 4 shows the top 20 keywords defined by comparing the positive versus the negative English subcorpora.[18] The Sketch Engine keyword tool uses a parameter that has the effect of displaying either the rarer or the more common words in the keyword list. That parameter was set at its highest value (1,000,000) to select the most common words. Even so, we notice that, due to the nature of the corpus, some content words appear among the top twenty keywords (‘read’, ‘great’ and others). We will only look at the function words and notice that ‘you’, ‘he’ (and third-person possessive pronouns) as well as ‘a’ occur more frequently in positive reviews. Interestingly, when we reverse the comparison and look at keywords in negative versus positive reviews (results not shown here) we find ‘I’ (the other singular personal pronoun) and ‘the’ (as well as ‘not’, as predicted by Crossley et al.).
_vs._the_negative_(reference)_subcorpus.png)
Before trying to answer why these words occur in a positive or negative context, we will step up the level of abstraction and look at key POS-tags. Figure 5 shows the key POS-tags in the positive vs. the negative corpus.[19] There is much to note here, for example that third-person singular present-tense verbs occur more in positive reviews (tags VHZ (‘has’), VBZ (‘is’) and VVZ for other verbs), as do nouns (NN) and proper nouns (NP). In the reverse comparison (not shown here) we observe that past tense forms are more frequent in the negative reviews. Table 8 summarizes the observed differences.

An explanation of these differences begins with the observation that most NPs in the review texts refer to characters in the books, and only to a lesser degree to authors, places and book titles. One explanation would be that positive reviews more often than negative reviews recount part of the story. That explains the proper nouns, the use of ‘he’, the third person verbs, and also the present tense, as reviewers generally use the present tense to report on the story. A brief inspection shows that indeed most occurrences of NPs in the review texts are used to describe events from the story, with description or praise of authors as second most important category. But a systematic annotation effort would be necessary to validate this impression.
This hypothesis is also consistent with the observed difference between the usage of the determiners ‘a’ (mostly with positive reviews) vs. ‘the’. In general, ‘a’ is used to introduce new subjects into a text, while ‘the’ is used to refer to subjects already known. Table 9 shows nouns occurring after the definite or indefinite article, ordered by the fraction of occurrences after ‘a(n)’. The table is split in two halves: Words above the bolded bar (under ‘relationship’) occur disproportionately more with ‘the’, the words below co-occur significantly more often with ‘a(n)’. The words below the bar include the fixed expressions ‘a bit’ and ‘a lot’, but also general nouns that you would need to (begin to) recount a plot: ‘a man’, ‘a girl’, and many others. So, it makes sense that ‘a(n)’ should occur more in positive reviews. The words above the bar, especially the highly frequent ones, refer to objects that in the context of the review do not need to be introduced, and will therefore usually have ‘the’: ‘the book’, ‘the story’, ‘the end’, ‘the author’.
If positive reviews more often recount events from the story, is there also something that negative reviews do more? We note that in our corpus, the negative reviews are on average longer than the positive reviews (mean of 123 compared to a mean of 106 words). What do they use these words for? One possibility is that negative reviewers feel more need to explain why they didn’t like a book. An exploratory analysis using LIWC showed that negative reviews score significantly higher in all cognitive aspects (insight, cause, discrepancies, tentative language and differences), except certainty. These explanations may be regarded as a reviewer’s description of their individual cognitive and emotional engagement in the reading experience, which may explain the higher use of ‘I’ in the negative reviews. The results also suggest that explanations predominantly use the past tense, which could explain the predominance of the past tense in negative reviews.
This is only the beginning of a more extensive analysis: there are many other aspects of these keyword lists that merit further investigation. Why does, for instance, ‘and’ occur more in positive reviews? An explanation could be that positive reviews use more groups of three words to describe (especially) characters: ‘strong and determined and feisty’, ‘pretty and quirky and cool’ or ‘lost and lonely and unsure’. Another finding is that question marks are a very good predictor of negative reviews (and, confirming the findings of Taboada et al., these questions are indeed often sarcastic or rhetorical). We cannot go into these and other phenomena for reasons of space.
Conclusion
In this article, we looked at what an application of corpus-linguistic methods to online reviews can teach us about evaluation practices on online reviewing platforms. So far, there is no dominant research approach applied to online reviews, and up to now only a limited number of researchers have used corpus-based methods for their analysis. With some misgivings about its proprietary nature, we used Sketch Engine as the workbench with which to analyse them.
We looked at four questions about the online reviews. To answer the question whether online reviewers focus predominantly on their reading experience, bringing in their personal histories and other elements foreign to the book, we looked at a Word Sketch of ‘plot’. We saw that online reviewers demonstrate a rich conceptualization of the dimensions of ‘plot’ and other key aspects of literary appreciation. In asking whether reviewers of literary books differ from reviewers of suspense books in what they consider beautiful, we used a word sketch difference. We found that suspense reviewers prefer character and plot (as well as the dimension of the books’ materiality, the cover), literature reviewers prefer stylistic aspects and story. We also looked at the role of the body in reading. From our analysis it emerged that positive reading experiences are often described in bodily terms, either literally or metaphorically. Finally, we investigated differences between positive and negative reviews. We concluded that positive reviews recount more events from the story, while negative reviews explain in cognitive terms, and from an individual perspective, why the book was a disappointment.
Taken together the findings show that online book reviews, when studied in large numbers, reveal patterns that do not appear at the level of the individual review. A corpus tool such as Sketch Engine provides a useful lens for studying these patterns; its useful tools include keyword computations and word sketches. For all of the questions that we discussed in this article, we have only been able to scratch the surface, but it is clear that online book reviews provide an important opportunity for research into the question how literature and fiction more widely can affect readers. To reuse the phrase that an anonymous Amazon reviewer used about Murakami, for the researcher these reviews can be ‘a pretty sublime mix of WTF and OMG.’
Acknowledgements
I thank Marijn Koolen for preparing the English corpus. I also thank named and unnamed reviewers for their advice.
Translation mine.
See, for instance, Stephen Ramsay, “Who’s in and who’s out,” Defining digital humanities. A reader Farhnham/Burlington, Ashgate, 2013.
In fact, the author of this article could (perhaps) have hand-coded every query of which we will see the outcome in the following pages. That would have resulted in a number of Python programs that could have been made available for inspection through the journal’s repository. Instead, I chose to use Sketch Engine, to which I only have temporary access thanks to the EU Elexis project, access that will end three months after writing these paragraphs. My readers will not be able to repeat my computations within an open-source software and neither of us will be able to check the algorithms applied to produce their outcome. If I am unlucky, and the paper’s reviewers ask me to redo some of the computations with different parameters or different data, I may be unable to satisfy their request. Or I would have to take a subscription to Sketch Engine that will cost me or my employer at least € 500 per year (the price of a single-user academic license, including the required space for the corpora used in this study, but not much more. See https://www.sketchengine.eu/prices-for-academic-personal-accounts/, access date Dec 14, 2021). And even then, the algorithms might have changed, leading to different results, without me being able to do much about it. Is this an indefensible choice? I don’t think it is. It would have cost me an inordinate amount of time to develop the required algorithms myself. But this is not just about time, it is also about trust. For some things, if you are not a professional, you have to trust professionals, in this case, the makers of Sketch Engine. My algorithms would certainly have contained bugs. They would have taken ages to run, as I have neither have the time, nor, probably, the skills, to optimize the algorithms and have no access to servers with powerful CPUs. It would have been impossible for me to dynamically query the data, proceeding by trial and error, running interesting queries, modifying them and running them again to gradually reach a better understanding. On the contrary, each idea would have had to be tried out running scripts that would have taken too long to wait for their results, forcing me to switch to other tasks in between and so taking the momentum out of the work.
For a look at alternatives, see a.o. Adam Kilgarriff et al., “The Sketch Engine: ten years on,” Lexicography 1, no. 1, 2014; Laurence Anthony, “What can corpus software do?,” in The Routledge Handbook of Corpus Linguistics, Routledge, 2022; Andressa Rodrigues Gomide, Corpus Linguistics Software: understanding their usages and delivering two new tools, Lancaster University (United Kingdom), 2020.
Sketch grammars are available for many languages besides English. The grammar for Dutch is described in Carole Tiberius and Adam Kilgarriff, “The Sketch Engine for Dutch with the ANW corpus,” in Fons verborum, Leiden: Instituut voor Nederlandse Lexicologie/Gopher, 2009.
The list of frequently used adjectives is one of the grammatical relations that Sketch Engine shows for nouns. Others include ‘prepositional phrases with plot’, ‘plot is a …’ and the ‘nouns modified by plot’ and ‘plot and/or …’ that we will see later in this section.
See for an explanation of the LogDice statistic: Lexical Computing Ltd, Statistics used in Sketch Engine, Lexical Computing Ltd, Brighton, UK, 2015, https://www.sketchengine.eu/wp-content/uploads/ske-statistics.pdf.
Kutzner et al. find that only 4 % of the reviews discusses the relation of the book to the reviewer’s emotions: Kutzner, Schoormann, and Knackstedt, “Short Exploring the content composition of online book reviews.”
From a gender perspective, it is striking how many of these words refer to feminine characters: woman, girl, daughter, wife, lady, princess, heroine, sister, widow, maiden. ‘Man’ and ‘boy’ are the only ones referring to masculine characters. This would be worth a study in itself.
Subcorpora can be defined in Sketch Engine based on metadata of the corpus texts, known in Sketch Engine as ‘text types’. For most reviews in the Dutch corpus we know the reviewed book’s NUR code, a publisher-assigned genre label.
And ‘cover’, also interesting.
For example Winfried Menninghaus et al., “The emotional and aesthetic powers of parallelistic diction,” Poetics 63, 2017.
See also Marco Caracciolo, “Degrees of Embodiment in Literary Reading,” in Expressive Minds and Artistic Creations: Studies in Cognitive Poetics, 2018; Ben Morgan, “Embodied Cognition and the Project of the Bildungsroman: Wilhelm Meister’s Apprenticeship and Daniel Deronda,” Poetics today 38, no. 2, 2017, https://doi.org/10.1215/03335372-3869287; Christian Benne, “Tolle lege. Embodied reading and the “scene of reading”,” Language sciences (Oxford) 84, 2021, https://doi.org/10.1016/j.langsci.2021.101357.
I removed the ones which upon inspection turned out to be used more with story-world phenomena such as trees or heiresses, ‘breathtakingly’, ‘strikingly’, ‘so’, ‘exceptionally’ and ‘extremely’.
See for example Tom De Smedt and Walter Daelemans, ““Vreselijk mooi!” (terribly beautiful): A Subjectivity Lexicon for Dutch Adjectives.” Paper presented at the Proceedings of the 8th Language Resources and Evaluation Conference (LREC’12), 2012.
“The development and psychometric properties of LIWC2007,” 2007, accessed 2017-01-24, http://hdl.handle.net/2152/31333.
We ignore reviews with rating zero, which presumably represents a missing value.
After the first ten to twenty keywords, the differences in relative frequency quickly get so small that, while still statistically significant, it becomes hard to ascribe meaning to these differences. For the algorithm that Sketch Engine uses, see Adam Kilgarriff, "Simple maths for keywords. " Paper presented at the Corpus Linguistics Conference, 2009.
The meanings of the tags are explained here: https://www.sketchengine.eu/english-treetagger-pipeline-2/ (access date Dec 14, 2021).