




1. Introduction
Throughout the past two decades, viral trends—from the “ice bucket challenge” to #cottagecore—have come and gone. But some major genres of viral media, like memes or gifs, have enjoyed a more perennial popularity. One of these genres is the digital prank. Pranks, considered most broadly, are events in which one party or group (the prankster) puts another party or group (the victim) in an engineered situation, beyond their full comprehension, for comedic or other effect. A sister pours salt in her brother’s milkshake. A man tells his friend— falsely—that his car is being towed to cause him to run outside to the parking lot in panic. “Media pranks,” more particularly—as Kembrew McLeod has defined them—are pranks that appear either as depicted within or orchestrated through popular media (“Media” 1725-1731). Since the early 2000s, media pranks have emerged in new digital forms, appearing across platforms for popular video like YouTube, Vine, TikTok, and Kick. These platform-based media pranks—or “digital pranks,” hereafter—have inspired fluff-pieces, memes, and public debates (Chen; Fleming). In her 2023 survey of digital celebrity, Extremely Online, tech-cultural journalist Taylor Lorenz mentions “prank,” “pranks,” or “pranking” thirty-eight different times (across nine of twenty-one chapters).[1] She tells the story of an infamous 2015 YouTube video titled “Killing My Best Friend Prank,” in which a creator named Sam Pepper pretended to kidnap two of his friends and then to murder one at point blank range while the other watched (211).
Digital pranks like Pepper’s, in particular—of a sadistic, dangerous, or dubiously authentic kind—have inspired much commentary (Tait; Sung; Böhner). Pranks such as these—which have resulted not only in doxxing, but in arrests and even deaths (Fleming)—raise some of the most urgent types of questions that platforms now pose from sociological and political perspectives: questions regarding content moderation, misinformation, adolescent mental health, and even political polarization. Platform pranksters like Logan Paul and the “Nelk Boys,” as The New York Times recently reported, have touted right wing causes like immigration restriction and anti-wokeness, and lent their support to Donald Trump on the 2024 campaign trail (Branch). From other perspectives, however, the digital prank genre may inspire different queries. Critics working in aesthetically-oriented and cultural critical fields, for example, though not uninterested in platform-based media’s most acute social urgencies, may approach this new media’s significance from a somewhat different angle, attending more to its broad-ranging textual, aesthetic, or experiential properties. Regarding a genre like the digital prank, they may ask both general and interpretive questions, like: How pervasive are pranks amongst other viral genres? And what might they reveal about popular platform video as a cultural form?
By exploring these questions, this essay reconsiders the digital prank from an aesthetic and cultural critical perspective. At the same time, it engages in a methodological discussion: it addresses some of the obstacles and opportunities that emerge when we approach platform content in a manner at once aesthetic and “generalizing,” seeking to relate narrower cultural “canons,” or sub-types, to larger “corpora” (Piper). This kind of approach has not been uniformly embraced by humanist critics. But it has—as I will soon address in more detail—been both foregrounded and refined within the digital humanities. In a founding 2016 essay for this journal—as well as in his 2020 book Cultural Analytics—Lev Manovich called for a digital humanities that would bring a broadly aesthetic and computational perspective to platform culture, addressing the likes of Instagram images or reddit posts. Since then, such a method of inquiry has only partly manifested. Digital humanists have, of course, begun to study social media, and in some cases they have examined platform content most broadly construed (Antoniak et. al, Le Khac et. al., Zhou et. al). Mostly, however, this research has remained tightly focused on content which explicitly addresses traditional objects of humanistic inquiry, like literature or art (e.g., Goodreads or BookTok). (Herrmann et al.; Thomas).
In this article, using the digital prank as my proxy, I pursue a (computational) humanistic approach to popular platform content both synthetic and aesthetic. So doing, I address some of the complications that crop up for this program of study. Two problems occupy my attention, more particularly. The first is a problem of generalization, which closely resembles what internet studies scholar Ethan Zuckerman has recently dubbed the “denominator problem.” While platforms have generally made it more-or-less simple to collect data regarding subtypes of content, like #BLM tweets or makeup tutorials, they have often made it more difficult to collect data that represents popular platform content more holistically. While it is possible to consider a viral genre like the prank in isolation (as a “numerator”), it is more challenging to consider such a genre as it relates to a broader landscape of viral videos (a larger “denominator”). The second problem concerns aesthetic description, and resembles complications that have been perennial across prior digital humanistic work analyzing literature or other arts. Namely, it can be challenging to address aesthetic media—in the case of this essay, platform content—in manners that are scalable but also sensitive to formal and interpretive subtleties. Where approaches like computational modeling or human annotation can make it possible to address platform content in large quantities, such methods can also encourage the consideration of aspects of this content that are relatively simple or reduced, like its most basic and familiarly-defined generic categories (e.g., news or DIY) or thematic properties (e.g., concerning cooking or sports).
To work through these issues, I proceed as follows: First, I address the digital prank in relation to a broader collection of viral video. I begin by compiling two sets of highly-engaged videos using one of the better available methods for historical collection of popular content: I collect data concerning videos by the top-ranked English-language YouTubers from 2012 to 2023 and TikTokers from 2020 to 2023. I then analyze this data using mixed methods. I use an aesthetically-exploratory style of human annotation to identify and quantify digital pranks within the collections, as well as to determine the other videos’ most common generic categories. I then use combined methods of “close” and “distant” analysis—closely interpreting individual videos and computationally analyzing more aggregated samples—to address the relationships between the digital pranks and other genres of video identified. Though digital pranks appear consistently across the broader collections that I compile, they are outnumbered by multiple other genres which have not previously been given formal names or definitions. Moreover, while the digital pranks that I encounter are occasionally disturbing, violent, or boundary-pushing—as in the case of Sam Pepper’s “Best Friend”—they more typically reflect different types of common features of the other videos collected, like overt fictionality, fixations on visual pleasure, emphases on material processes, and a spirit of experimental curiosity. In my conclusion, I broach some final implications of this analysis. I consider how aesthetic approaches to popular content can help us expand and diversify the sorts of “canons” of digital objects—to use a metaphor carried over from humanistic and art-critical fields—to which new media studies can attend.
2. Pranks, From Print to Platforms
A full history of the media prank, as well as of its critical appraisal, is beyond this study’s scope. One point, however, requires making: media pranks have often reflected, not only the shifting conditions of their mediation, but also broader cultural preoccupations. In eighteenth and nineteenth century England and America, for example, media pranks flourished—as McLeod describes—in the form of print-newspaper hoaxes (Pranksters). Two prominent examples were twin tricks that Jonathan Swift and Benjamin Franklin played in 1708 and 1733 in which they took up pen-names to publish pieces predicting the impending deaths, on amusingly precise dates, of celebrity astrologers. Hoaxes such as these were shaped partly by a print-media culture which lacked guardrails that might curb fakes, frauds, and forgeries (like journalistic guilds or effective libel laws). These pranks also channeled emerging fusions of Enlightenment rationality with secularized magic, as a new generation of “celebrity magicians exposed the ‘supernatural humbug’ of shady charlatans” (McLeod, Pranksters 73). After World War II, American TV shows, from Candid Camera (1948-2012) and America’s Funniest Home Videos (1989-present) to Jackass (2000-2022) and Punk’d (2003-2012), took advantage of a videographic medium to portray media pranks in “real time,” centering on physical comedy and eye-popping stunts (e.g., many blows to the crotch). These shows, however—and as Benjamin Wiggins has proposed— also channeled what Horkheimer and Adorno diagnosed as an advanced capitalist “sadism,” harnessing instrumentalized reason in the service of a clinical style of domination. (“Mechanical planning makes up 90 percent,” as Wiggins puts it of one TV prank, “suffering and ridicule make up the rest”). Even the relatively wholesome Candid Camera was partly inspired by the Milgram experiment (Wiggins).
Today, a new type of media prank emerges. Since the early 2000s, digital pranks have attracted attention on video-centric platforms. Like their precursors, these pranks reflect their specific mediations. In an environment emphasizing “user-generated” entertainment, in which increasingly professionalized “amateurs” churn out new content from their basements incessantly, digital pranks are both easily produced—requiring nothing but an iPhone and a victim—and endlessly iterable. Consider, for example, the TikTok channel “Wigofellas,” on which an unnamed young man regularly posts daily videos of pranks played on acquaintances.[2] Digital pranks are also meme-able and remixable, allowing for “prank challenges” or “trends,” as in repeated iterations, by different creators, of the “escalator prank,” which takes place on an escalator, or of the “kissing prank,” which involves tricking someone—usually a woman—into a kiss.[3] Like their media prank precursors, digital pranks undoubtedly reflect their moment. What might they reveal about more general cultural patterns or preoccupations?
Existing work on the digital prank genre has not emphasized such generalizing questions. One strand of this work has approached digital pranks from the perspective of the social sciences. Spanning fields from psychology to advertising, this work has used small subsets of digital pranks to pursue targeted disciplinary questions, concerning intimate partner “sadism” (Jarrar et al.), child facial “emotion recognition” (Shuster et al.), or platform-based “brand perceptions” (Karpinska et. al; Chang). Another strand of work on the genre spans both journalism and academia and proceeds in more cultural critical fashion. This work has been restricted, however—as far as the aims of this essay are concerned—in two respects. It has considered digital pranks largely in isolation, rather than in relation to broader cultural historical implications; and it has focused more narrowly on digital pranks of an especially sadistic, edgy, or corrosive kind. Three journalistic pieces which critique the prank genre, for example, have done so through the lens of a few infamous case studies (Tait; Sung; Chen). In a more scholarly context, Wiggins has focused on the “sadistic” YouTube pranks featured on the 2009-2012 TV show Pranked, while Max Böhner has collected a “small sample” of YouTube pranks featuring “young, white, heterosexual, able-bodied, oftentimes muscular and sometimes overtly sexualised” creators to discuss toxic masculinity (73). One might observe on perusing this literature that a small “canon” has begun to emerge. Three of five of these pieces, for example—and like Lorenz’s Extremely Online—discuss Pepper’s “Killing My Best Friend.” Four of five consider the same cruel digital prank produced by a creator called “DaddyOFive.”
3. The “Denominator Problem”
By contrast with prior work, which has engaged the digital prank largely in isolated samples, I aim to address how the genre reflects wider cultural currents. To this end, I take inspiration from lineages of broadly diagnostic, humanist criticism—from Jameson’s Postmodernism to Kornbluh’s Immediacy—while drawing more directly on the work in the recent digital humanities that has honed this type of cultural-critical “generalization.” In his 2018 Enumerations, for example, Andrew Piper argues that computational and machine learning tools can refine humanist methods of working from “canons” to “corpora,” relating much-discussed subsets of texts (like Kafka’s novels) to more encompassing categories (German Modernism). With more specific reference to “genre,” critics like Ted Underwood, Ryan Cordell, and Matthew Wilkens have used clustering and classification to map genre-scapes across cultural collections and then relate single genres to the wider array—if with care, as many have encouraged, to avoid fantasies of totality (Wasielewski 60). Such methods would seem, as Manovich has proposed, fruitful to apply to popular platform content. And indeed, the genre of the digital prank appears to provide one opportunity. Where prior studies of the digital prank have focused on samples of the genre considered independently of other types of platform content, we might instead consider such samples as they relate to larger, more generalized corpora of viral video.
To do so, however, presents complications. The first involves what Ethan Zuckerman has recently dubbed the “denominator problem”: While popular platforms throughout the past decade or so have made it relatively simple to collect data concerning narrower categories of content—like #MeToo tweets or PewdiePie videos—these platforms have made it more difficult to collect data concerning content more generally. Whether researchers have used front-end collection or APIs, they have typically been able to search for data concerning content by keywords, creators, or hashtags, but not in the form of more random or comprehensive samples. In this sense, certain “numerators” of content can be tracked but not broader “denominators.”
The denominator problem becomes more acute when attempting to collect data concerning random samples of especially viral or highly-engaged content—and especially for past time periods. Elsewhere, I have established this point regarding multiple major platforms (McNulty). For the purposes of this article, the examples of YouTube and TikTok are most relevant. The YouTube Data API makes it (overtly) impossible to collect data concerning random samples of either videos in general or above some engagement threshold (e.g. one million views), by restricting searches to fields like keyword or creator. Though the tool does include a function to call up catalogues of “popular videos” in geographic regions, these lists—like front-end “trending” content tabs—are both restricted to the present moment and opaquely defined. In their article “Dialing for Videos: A Random Sample of YouTube,” McGrady et. al create a hack for collecting a random sample by generating arbitrary 11-digit video ids and then scraping whichever videos exist. This method, in addition to being time intensive and potentially violating the YouTube “Terms of Service” (the official API cannot be used, due to quota limits), favors the collection of unpopular videos. The sample of 10,000 videos that McGrady et. al collect over three full months contains only 3.67% videos which earned 10,000 or more views, already a modest threshold for virality. TikTok presents other problems. Though the platform now offers a research API, the tool has been reported unusable for various reasons, including a foreboding set of “TikTok Research Tools Terms of Service” and major disparities with front-end content (Steel et al.). Confronting these issues, Steel et. al have recently developed a slightly more complex “dialing for videos” method for compiling a near-comprehensive sample of TikTok videos created at a particular moment. This method, however, is best suited to collecting videos posted during a narrow time window, like a single hour or day, and therefore produces data that may best reflect fleeting trends.
It will be difficult, in sum, to collect a truly representative sample of the most-engaged content on YouTube or TikTok during a reasonably broad span of these platforms’ recent histories. Therefore, it will be difficult to address the types of questions that this essay has posed about the digital prank. In the absence of a broader viral denominator, it will be challenging to gauge the genre’s actual prominence. Indeed, in his blog post concerning the denominator problem, Zuckerman specifically emphasizes how the obstacle impedes researchers’ abilities to discern how common or popular types of content like fake news are relative to platform content as a whole. Lacking general samples of content, however, will also frustrate this essay’s more central aim: to consider not only how prominently digital pranks appear across collections of viral video, but also how they might reflect broader patterns across such data.
4. Data: Pranks’ Prominence
Fortunately, there are imperfect solutions, enabling me to consider the digital prank as it relates to some type of more long-term viral denominator. While collecting viral videos writ large may be challenging, collecting data concerning videos by top-ranked creators is a useful alternative for covering historical timescales. Here, I collect data concerning all videos by top-ranked English-language creators on both TikTok and YouTube—the two largest video platforms both in the U.S. and globally—during periods that cover much of their U.S.-based heydays: for TikTok, 2020-2023; for YouTube, 2012-2023. This data, which is biased toward content produced by mega-popular creators, will not precisely stand-in for the most popular content that has appeared on these platforms. In the absence of other publicly available alternatives, however, it represents one of the better means available for surveying historically top content on these platforms.
4.1. Data Collection
To collect this data, I worked with two research assistants at the University of Illinois.[4] First, we collected lists of top-ranked TikTok and YouTube creators, as published online by the aggregator Social Blade. I then personally filtered these lists down to retain only creators whose channels appeared to produce content catering primarily to English-language audiences (and in a few other ways, for YouTube). I performed this language-based filtering for two reasons. First, due to my background in the study of American and global Anglophone aesthetic culture, my interest in this article was in viral videos which might be consumed by U.S.-based and/or global English-speaking audiences. Because demographic information regarding the nationalities of the audiences of the top-ranked creators’ channels was not publicly available, filtering the channels by language provided a proxy for targeting those audiences. On a more practical level, English was the only common language shared between myself and my research assistants, so carefully analyzing videos in non-English languages was beyond our collective capacities. More than half of all top-ranked channels for both platforms produced content primarily in English (see subsequently reported numbers); others produced content in languages like Russian, Spanish, and Hindi. After I filtered the lists by language, we collected all videos produced by each creator during the years when they appeared on the top-ranked lists and above a view-count threshold. I then took smaller samples of these videos balanced by videos per creator, for the purposes of closer analysis. The process was similar for each platform with a few key distinctions.
To collect and sample the TikTok data, we began by locating the media aggregator Social Blade’s regularly updating lists of top-100 ranked TikTok creators by subscribers. (Social Blade, like other corporate analytics companies, can compile top lists through a combination of special access—like higher API quotas—long term tracking, and creator buy-in.) Using the Internet Archive API, we collected all available past published versions of the Social Blade listings from 2020 to 2023. We then aggregated these lists and removed duplicates, producing a final list of 195 top TikTokers with subscriber counts spanning about 30 to 150 million. Next, I personally filtered this list to include only creators whose content during the years of their top-ranking was produced in English and appeared to be geared to English-language audiences. To make this determination, I read the channel description, scanned all titles/captions of vides produced during the top-ranked years, and watched three randomly-selected videos. In a small number of cases that were difficult to adjudicate, I watched two additional randomly-selected videos (five total). In these tricky cases, a creator labeled videos with English captions but performed them in other languages; I retained these videos when the creators did not rely heavily on dialogue for comprehension. Once I excluded 55 non-English channels and 22 with no current front-end presence (sometimes due to changed usernames/pages), 118 remained.
Using a front-end manual collection tool called zeeschuimer, we then collected metadata for all videos produced by these 118 TikTokers during years when they appeared on the top-ranked lists, where still available on the platform (n=83,552).[5] The benefit of using the scroll-through tool was that, by some arguments, it does not violate the platform’s “Terms of Service” (i.e. not “automated” collection); a downside was that it collects links to videos, along with other metadata (creator, caption/title, date, metrics), but not full videos, meaning that some links might lead to removed or blocked content or go dead during analysis (a topic I will return to). Once all video data was collected, a small group of videos earning especially low view counts was excluded (<1%, <10k views). 115 creators remained with at least 10 videos each. Two smaller samples of these creators’ videos were taken, with replacement: one of 10 randomly sampled videos per creator (n=1150) and another of 5 randomly sampled videos per creator (n=575). Summary data for each sample—TikTok set 1 and TikTok set 2—is included in Table 1. Throughout this essay, I will refer to these samples as the “target” sets, used for formal analysis. I also collected a few other “practice” sets for the purposes of more informal explorations of the data. Practice sets included no overlap with target sets.
For the YouTube videos, we repeated a similar process with some distinctions. First, all available top listings were extracted from the Internet Archive, 2012-2023. Next, a master-list of 378 top creators—or channels—was culled, with subscribers ranging from 500,000 (in 2012) to 250 million (in 2023).[6] Channels were then filtered to exclude non-English channels. I again used the same process of reading each channel’s description, scanning all titles/captions of videos produced during the top-ranked years, and watching three randomly selected videos. (In the context of YouTube, I did not need to watch five videos for any tricky cases.) When non-English channels were removed, 230 remained. Here, however, one other step of channel-filtering was also performed. When examining the channels, it became clear that many—like “CocoMellon Nursery Rhymes” or “Like Nastya”—were oriented toward very young children or toddlers. (TikTok channels, by contrast, often felt geared toward teenagers, but not toddlers.) Others were channels that predominantly posted minimally re-packaged content from or associated with prior media, like music videos or largely-unaltered TV clips (e.g., on the BBC channel). During the process of filtering the channels by language, therefore, I also identified and labeled these other types of channels. If a channel appeared to be devoted primarily to content for young children, and all three examined videos fit this description, I labeled the channel “Kids.” If a channel appeared to be devoted primarily to music videos, and all three videos fit this description, I labeled it “Music Videos.” If a channel appeared to be devoted primarily to largely unaltered TV clips, and all three videos fit this description, I labeled it “TV Clips.” I decided to remove the Kids, Music Videos, and TV Clips channels prior to subsequent analysis—though this was, admittedly, a judgment call—in order to target the sort of adult/adolescent-oriented or “platform specific” content that one might have in mind when asking about historically emerging forms of “viral” or popular video (or, at least, that I had in mind). That said, it should be noted that these types of excluded channels comprise a large proportion of top-ranked, English-language channels on the platform—indeed, more than half of those that I surveyed (148/230) (see Figure 1). Once these channels were removed, 82 remained.
Next, we used the YouTube Data API to collect metadata for all videos produced by the remaining 82 channels during their years on top lists (date, URL, title/subtitle, metrics), insofar as this data was still available (it was for 60 channels; n=14,797). Again, full videos were not available through this non-TOS-violating method. We then filtered the data to exclude videos with relatively lower view counts, earning less than 500,000 views (54 channels and 10,604 videos remained). Here, a higher view-count threshold was imposed than for TikTok. Though this meant that the TikTok sets, by comparison, each included a small number of videos falling below this higher threshold (<6% of videos at <500k views for each TikTok set), the final TikTok and YouTube sets had comparable mean view counts (Table 1). No adjustment to the threshold was made, by year, for platform inflation, despite the YouTube’s data’s longer timescale; the threshold represents an absolute number of views and not a relative proportion of platform engagement. At this point, 49 channels remained which had at least 10 videos each. We took two small samples, with replacement, of 10 randomly selected videos from each, creating YouTube sample 1 (n=490) and YouTube sample 2 (n=490) (Table 1). Again, practice sets were also collected.

These datasets, of course, represent only a vanishingly small portion of the videos appearing on both platforms. Samples of roughly 500 to 1200 videos are, by quantity alone, a drop in the ocean of platforms that may host almost 10 billion videos total (estimated for YouTube in 2022 (McGrady et al.)) or receive uploads of 5 million videos per hour (estimated for TikTok in 2024 (Steel et al.)). But while small in abundance, these videos represent a class of video—globally top-100 ranked creator video—that is massive in popularity. Mean view counts for the videos in my four target sets spanned roughly 10 to 16 million (Table 1). Indeed, this type of mega-viral content may attract an even larger share of audience attention than has been presumed. “The ‘long tail’ of YouTube,” as McGrady et. al find, “is very, very long.” Of the 10,000 videos in their random sample, “the 16 most popular…are responsible for more than half of all views.” McCabe and Hindman have argued that “top” platform content represents broader platform offerings surprisingly well, given that “nearly all platforms concentrate users in a few high-volume places.” Some, however, have suggested that TikTok uniquely populates individual feeds with larger quantities of more relatively obscure videos (Abidin).
4.2. Labeling Pranks
How prominent are digital pranks within this data? To begin to get a sense—and, again, with the help of two assistants—I engaged in a process of double annotation. For each target set, one pair of coders—myself and one other—moved through the links listed in the set and followed them to watch each video. For TikTok, we watched the full video; for YouTube, we watched a minimum of the first five minutes and then skimmed the rest as deemed necessary to assign a label. Next, using the definitions laid out in a codebook, we labeled each video as “Prank” or “non-Prank.” In some cases, the video could not be labeled because the URL now pointed to a page stating that the video had been removed or could not be viewed. In these cases, we marked the links as “dead,” flagging them for removal from the sets. This loss of data was a byproduct of using non-TOS violating (or, in the case of TikTok, potentially non-TOS violating) methods of data-collection, compiling links but not videos. Finally, after separate rounds of labeling, we met to discuss all diverging labels and reach consensus decisions.
To create the codebook, I watched digital pranks located on the front-end of both platforms by creators not included in the sets. After composing a working definition, I discussed the definition with the annotators and we revised for clarity and accuracy. The final codebook can be viewed in the project’s Dataverse repository and lays out operative definitions: a montage of pranks was a prank; a fictional prank (e.g., in a cartoon) was a prank; a happy surprise—like hiding a present in a friend’s shoe—was not a prank, despite some structural similarities. I first labeled the two TikTok sets with one other annotator and then the two YouTube sets with another. In each case, we first trained on one practice set.
In all but one round of initial independent labeling, Cohen’s kappa for inter-annotator agreement exceeded 0.60. For TikTok set 1, it was 0.58. Still—and for reasons to be discussed further, shortly—the final labels agreed upon through subsequent discussion were retained. Furthermore, before taking final tallies of the labeled videos, the effect of the presence of dead links on the data had to be considered. If dead links were scattered evenly across creators—causing a few creators to lose one or two videos each—then all creators could be retained in the sets without creating undue bias. If, however, the losses were more concentrated, causing some creators to lose most or all of their videos, then those creators should be removed. In the case of the two TikTok sets, dead links were more numerous, comprising 45/1150 videos in set 1 (3.9%) and 23/575 in set 2 (4%). Three creators were highly affected and therefore removed, leaving 112. For the two YouTube sets there were only three dead links in total, all occurring in set 1, and no creators required removal. Once dead links and highly-affected creators were removed, total numbers and percentages of pranks out of the remaining “live” videos were calculated.
As summarized in Table 2, pranks appeared modestly across the four sets—though perhaps less so than might have been expected for YouTube, in particular. For TikTok sets 1 and 2, pranks constituted, respectively, 4.71% (52/1105) and 6.00% (33/551) of live videos. For YouTube sets 1 and 2, they came to 3.29% (16/487) and 3.10% (15/490). Bootstrapped confidence intervals for these percentages, resampling creators with replacement, were calculated and appear in Table 2. For YouTube, the ranges could dip quite low—almost to zero—given what turned out to be the high concentration of pranks in these samples amongst a few creators. This suggests the possibility of less representation of the digital prank amongst content by top-ranked YouTubers than prior writing about the genre might have led one to expect. It may be the case, of course, that many pranks have simply been removed from the platform due to their controversial nature. Yet none of the creators known for those much-discussed, edgy pranks—like Sam Pepper, “DaddyOFive” or even Logan Paul—have ever historically appeared within the top 100 rankings, somewhat undermining that theory. The quantities of pranks reported here are too small to meaningfully index shifts over time. These quantities are also difficult to parse, as far as relative size, in isolation. To understand their implications, we must know more about the other genres appearing in the corpus. I turn to that topic now.
5. The Problem of Aesthetic Description (Genre Annotation)
How might these digital pranks relate to other aspects of the videos collected? Here, the aim will be to address not only these videos’ flat, thematic properties (e.g., about “video games” or “crafting”), but also their more expressive qualities. Capturing such qualities is something more of a subjective or interpretive enterprise, and has, for this reason, often been the province of the humanities. Within the digital humanities, options for doing so are often described as binary: “close” or “distant” analysis. Even within digital humanistic work, however, there are also other modes and scales of analysis. One is the often integral, but perhaps less rhetorically-emphasized process of human annotation. This method may be used as a preamble to supervised learning—for instance, when labeling training data for classifiers—or as a means of generating initial dataset descriptions. This latter role is emphasized across qualitative areas of new media studies and may play an equally helpful role in more DH-geared approaches to platform content.
Again, however, complications arise. If the aim is to capture more aesthetic types of properties, then even processes of human annotation, as much as “distant reading,” may involve some substantial reductionism by comparison with “close reading” (and in manners less thoroughly discussed in digital humanistic contexts). One difficulty for human annotation, when it comes to identifying aesthetic properties, concerns the expectation of meeting benchmarks for inter-annotator agreement by metrics like Cohen’s Kappa. This requirement may encourage the consideration of the types of flattened or conventional categories which labelers can easily recognize and agree upon, like “pets and animals” or “music” (as in McGrady et al.'s labeling of their random YouTube sample). One potential solution—as embraced in my prior process of labeling pranks—is to relax thresholds for inter-annotator agreement and/or then more collaboratively reconcile diverging labels. This process has precedent in studies of platform content within the digital humanities. In a 2019 article aimed at tracking the relatively interpretive category of the “microaggression,” for example, Breitfeller et. al address the need, in an initial annotation process, to embrace lower agreement benchmarks and then, in cases of disagreement, retain labels determined by a “follow up adjudication process” (1666). Even this type of flexible process, however, may encourage attention to categories that already have some conventional currency, as opposed to genres which have not already been given common names—a potentially important liability in a field addressing “new” media.
To explore two of my target sets—TikTok set 2 and YouTube set 2—I embrace a somewhat experimental process of human annotation, aimed at striking a balance between the richly descriptive “subjectivity” of individual close reading and more potentially flattening “objectivity” (or intersubjectivity) of collective labeling. First, I personally examined a practice set for each platform to come up with a labeling scheme that could capture the genres therein, by my own interpretation. The aim for each platform was to come up with categories that could comprehensively cover all the videos in the set so that every video—or almost every video—could theoretically be sorted into at least one bucket. The aim was also to capture not only basic themes or familiar genres (like gaming or dance), but also more novel formations.
Consider, for example, one type of video that cropped up often. In this type of video, some process was depicted involving the manipulation of material objects, which might include anything from food and craft materials (pottery, yarn) to soda bottles or balloons. Rather than dwell on the practical aim of showing viewers how to complete the process depicted, however—as in a tutorial/recipe, DIY, or how-to video—these videos, instead, placed more emphasis on the visual wonder of the process itself (often in vaguely hypnotic fashion). We see this, for example, in videos produced by the creator Bayashi, in which beautiful meals manifest at lightening speeds with no recipes provided, or by the illusionist Zach King, in which King appears to walk through a wall or pick up a car.[7] To capture this broad category as well as some of its internal variegation, I created a label which I called the Mesmeric Process Video—hereafter MPV—and four sub-categories: cooking (involving food); illusion; crafts or makeup; and material play (involving other materials).[8] This category relates partly to what others have called the “oddly satisfying,” “hands-and-pan,” “ASMR,” or, in the context of cinema, “process genre” (Skvirsky); but it is not precisely or fully captured by those terms.
After coming up with two separate lists of (often overlapping) genres that seemed to me to accurately capture the spread of videos across each platform, I drafted a sample codebook for each and then discussed it with my research assistants to revise for clarity and applicability. The final codebook with the full list of genre categories and sub-categories is suppled in the Dataverse repository. Tables 3 (for TikTok) and 4 (for YouTube) provide genre titles, abbreviated definitions, and sample links for most genre categories. (A few, which turned out to be less common in the target sets, are here excluded but appear in the codebook along with all subcategories.) Due to limitations of space, I will leave the more extensive discussions of all genres for future analyses. In the paper’s next section, I will discuss the genres most relevant to considering pranks’ relations to the broader collections.
Once the codebooks were complete, we proceeded to annotate the two target sets (after one round of training) by this schema: for each video in each set two coders, working separately, would assign at least one and up to two genre-category labels. If the video seemed to fit more than two categories, the two deemed most fitting would be chosen. Where a genre category with subcategories was selected, any applying subcategory would also be marked. The label “other” would indicate videos fitting no category and any new dead links that emerged (only one did, in YouTube set 2) would be marked for removal. Where a video was already labeled “prank” (information which was indicated) a second label would be added if deemed appropriate or the label would be changed if the annotator felt that two other labels carried more relevance (this occurred only once). Once the process was complete, the two annotators would meet to discuss all diverging labels and reach a consensus.
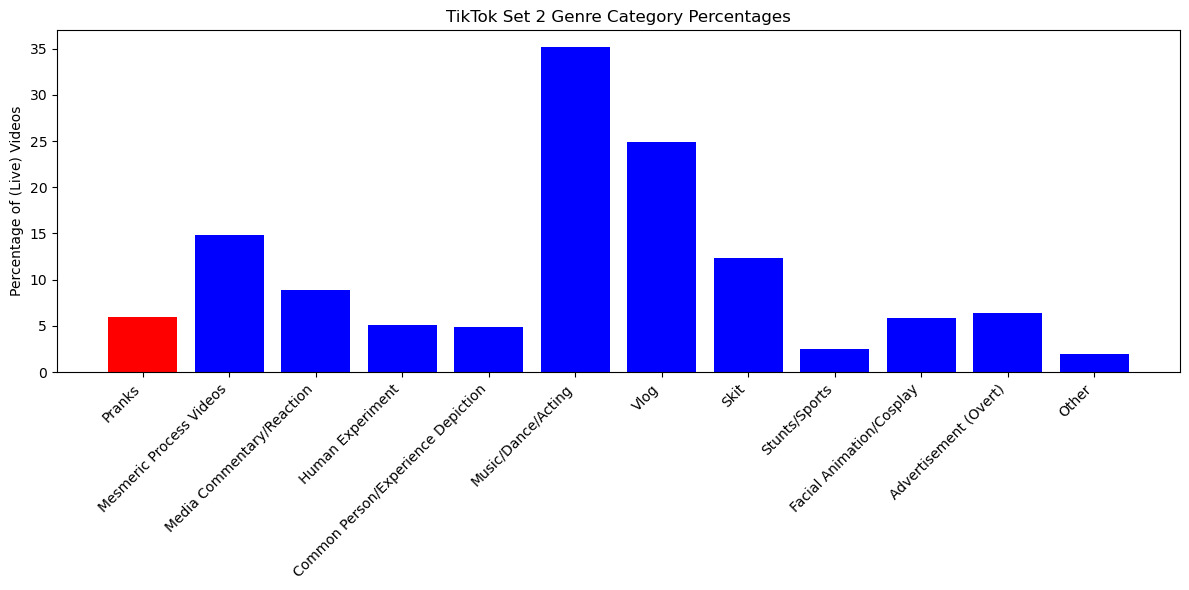
Due to the complexity of this scheme, inter-annotator agreement was not always high in the initial round of labeling—though, interestingly, higher than expected for multiple bespoke categories like the MPV. All agreement scores are included in the Dataverse supplement. Rather than being offered as grounds for any category’s removal, they are included to provide an indication of the difficulty of reaching consensus or perhaps, by extension, the “fuzziness” of different categories. Final genre quantities are represented in Tables 3 and 4, as percentages of total (live) videos that were given the label, along with bootstrapped CIs. Figures 2 and 3 represent the percentages visually. Because videos received up to two labels each, percentages do not add up to 100. Subcategory quantities appear only in the supplemental materials.

6. Pranks in Context: Analysis (Close and Distant)
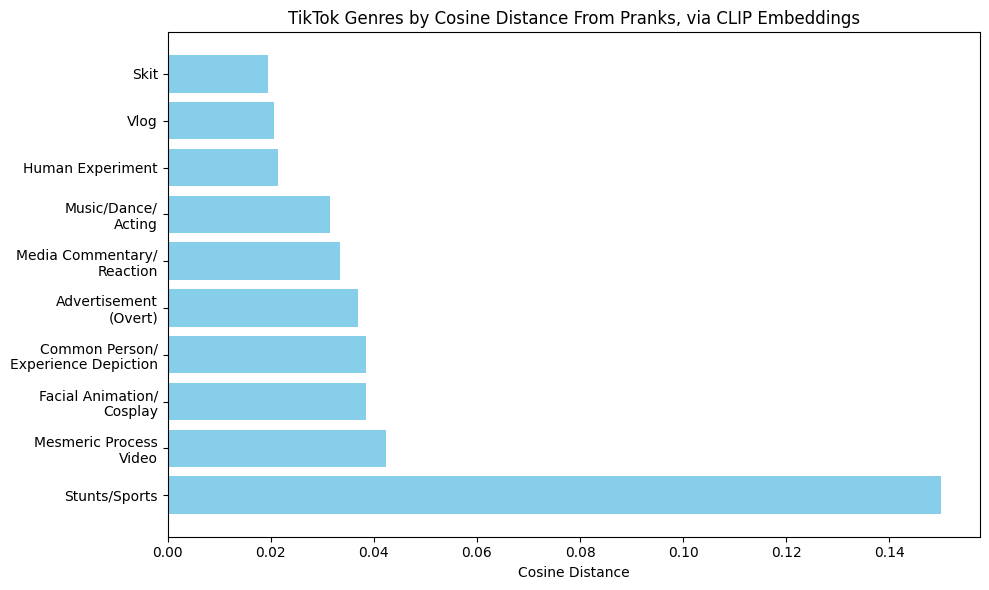
How, then do digital pranks in these sets relate to the broader collections? Based on the process of hand-labeling, I now proceed to “close” and distant" analysis. Though the discussion could extend at length, a few points are most pertinent to make. First, to return, momentarily, to the topic of the digital prank genre’s relative quantity, it is worth noting that while pranks do appear amongst the labeled genres, they are outnumbered, not only by familiar categories—like Gaming for YouTube (30.27%) or Music/Dance/Acting for TikTok (35.21%)—but also by more unfamiliarly-defined ones, like the MPV (TikTok: 14.88; YouTube: 10.63). Moreover, the 116 digital pranks culled from this data look different from those emphasized by prior commentators, in the sadistic vein of Pepper’s “Best Friend.”
One group of these pranks, for example, though overtly presented as “real” events (despite potentially being staged), rarely, if ever, involved tricks that might cause genuine harm. Pranks produced by the YouTube channel “JustForLaughs,” for example, which was responsible for many of the YouTube-based pranks, typically fit this description. In one, a man dressed as Christ creates the illusion that he is bringing a display of painted animals to life;[9] in another, an apparent statue—actually a painted man—sneezes periodically.[10] Playful music and a montage style underscore these videos’ lighthearted tone, more ‘aw-shucks’ than edgy. TikTok pranks of this allegedly real or documentary variety were also almost uniformly innocent: a creator blasts his flirting friends with a wind machine (David Dobrik)[11]; a boy puts a plastic snake on a can from which another will drink (Keemokazi).[12] Amongst the allegedly real pranks in these collections, I located only two that might be identified as more ethically boundary-pushing (in one, a child was repeatedly smacked with a roll of paper-towels; in another, a man’s facial abnormality was arguably mocked).
Another group of pranks, meanwhile, were similarly gentle, but in a different respect: these pranks, more skit than documentary, offered not even a pretense of reality. On the YouTube channel Tsuriki show, for example, two core performers, Vova and Anya, perform pranks of this variety, in an overtly artificial style. In one—in which both creators speak in the form of a comedic, record-scratching sound effect—Anya tricks Vova into believing that he has ripped his pants (Figure 4).[13] In another, Anya sneaks sweets behind Vova’s back, by pulling a comically large collection of candy from her bra.[14] TikTok pranks often conformed to this pattern. In one, two adolescents, after being tricked into kissing, bat eyelashes in cartoonish fashion (Sky and Tami);[15] in another, a boy narrates—in the third person—his clever plot to avoid his mother’s demands (Keemokazi).[16] The TikToker “Wigofellas” specializes almost entirely in hyperreal, cartoonish practical jokes (Figure 12). Rather than closely resembling reality-TV precursors, these pranks more directly harken back to vaudeville or early cinema slapstick. More analysis would be required to determine whether these gentle types of pranks have responded, if not to the abundance, then to the bad publicity surrounding edgier digital pranks.
.png)


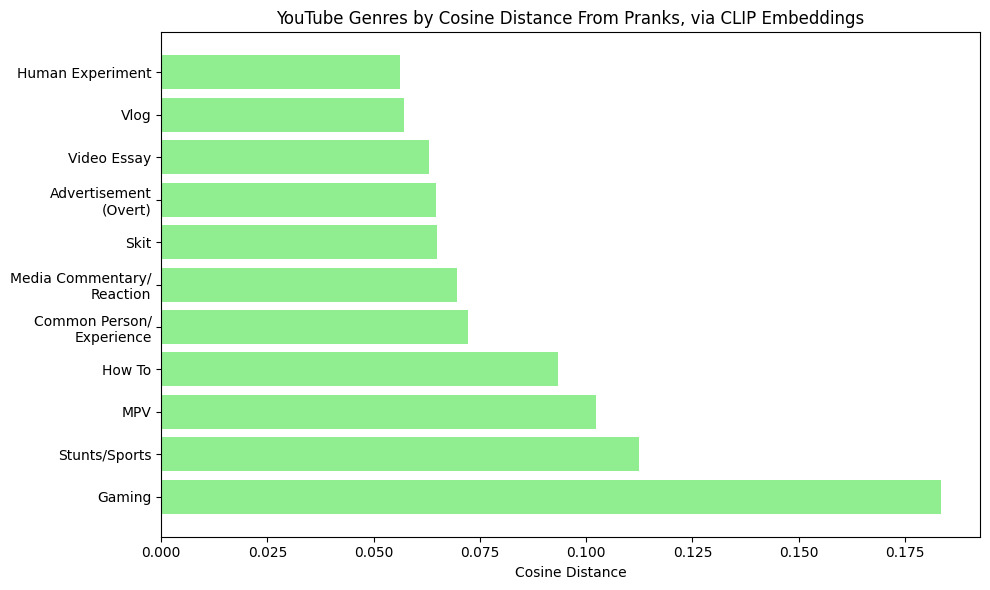
How do the pranks appearing in this data mirror genres appearing across the broader sets? Though extensive distant reading is beyond this essay’s scope, one computational method can help us assess the genre’s connections to one another. To begin to probe cultural distances (metaphorically speaking) between the pranks and other genres in the two genre-labeled target sets, I scraped the videos using yt-dlp (a less storage intensive process than scraping the full collections at an earlier stage).[17] Of the “live” 551 videos in TikTok set 2, twelve could not be scraped (they were dispersed across genres); of the 489 “live” videos in YouTube set 2, five were not scrapeable (and were also dispersed). I grouped the scraped videos by genre label, separately for each platform; I then generated embeddings for each video belonging to each genre using an OpenAI CLIP model (CLIP ViT-B/32) on eight uniformly-spaced sample frames per video. Frame-embeddings were averaged per video and then within each genre; cosine distances between the genres were then calculated to determine which genres were “closest” to pranks. The results appear in Figures 6 (TikTok) and 7 (YouTube).
A few of the proximities stand out. The TikTok genre deemed closest to the prank, for example, was the skit, confirming the commonality of overtly fictional TikTok pranks. Skits themselves comprised 12.64% of the TikTok and 19.63% of the YouTube videos. Both charts, too, reflect a close relative proximity between the prank and what I called the Human Experiment, a genre which comprised 8.59% and 5.08% of the YouTube videos and TikToks, respectively. In the Human Experiment, a creator designs or undergoes some quasi-scientific trial, with the aim of learning something about human beings or the world. Examples include the YouTube channel As/If’ s video in which a brunette woman dyes her hair blonde and then methodically gauges the alterations to her everyday experience (e.g., more Tinder matches)[18] and multiple scenarios constructed by Mr. Beast, like giving various members of the public one million dollars with only one minute to spend it, or testing out private islands at different price tiers.[19] The prank genre, like the Human Experiment, involves a scientific trial of sorts, creating controlled conditions to see how a victim will react (pranks, however, were not counted as part of the Human Experiment genre). Both genres are well-suited to the platform environment for their endless iterability; they embody a spirit of playful and yet methodical curiosity.
Close reading also suggests points of commonality between the digital prank and the MPV, regardless of the two genres’ more overarching proximity. Many of the pranks appearing in these datasets, in keeping with the MPV’s ethos, seemed to center less on the character-driven drama of the prank itself than on the fascination of the material manipulation through which the prankster ensnared their prey: the clever simulacrum of a broken iPad via a textured sticker;[20] the half-mannequin that creates the illusion of missing legs;[21] the cardboard structure that camouflages the trickster.[22] Again, such popular videos called to mind early cinema and what Tom Gunning famously referred to as its “cinema of attractions”: a style focused less on narrative or storytelling than on “presenting a series of views to the audience, fascinating because of their illusory power” (382, emphasis added).
7. Conclusion: Pranks and the Viral Canon
Generalizing textual analysis serves only as a starting point for more specific investigations. Though demographic data regarding most top-creators’ audiences is not publicly available, studies of reception might better illuminate for whom and why these videos become so visible. No collection—as this essay has emphasized—can reveal the viral past writ large. All manner of uncertainties pervade the data that I have compiled (who are these anonymous but mega-viral creators? What do metrics like view counts truly mean?). And yet, there is still much more to learn about the information regarding the popular digital past that remains publicly available.
Today, scholars, journalists, and other commentators have begun to construct early canons of the new media called only “content.” While some genres are quickly spotted, defined, and incorporated into critical analyses, others may, despite their massive visibility, hide in plain (critical) sight. Digital pranks are commonly considered to be a major platform genre, but they are outnumbered within this essay’s datasets by less familiarly-defined categories. While sadistic digital pranks like Sam Pepper’s may have become critical touchstones, gentler and more fictionalized iterations here abound. Considered through the capacious, interpretive lens of the (digital) humanities, a genre like the digital prank suggests an account of popular platform culture distinctive from many of the most prominent. Rather than embodying edginess, political acrimony, or corrosive irony, the viral videos addressed in this study are more overwhelmingly marked by sensory immersion, methodical experiment, and playful curiosity.
Data Repository: https://doi.org/10.7910/DVN/ANAYPO
Acknowledgments
I would like to thank the University of Illinois’s Humanities Research Institute (HRI) and Campus Research Board for providing funding that supported this project, Tanmoy Debnath and Manvik Nanda for their work as research assistants, and my co-editor Laura Chapot, as well as the editors and peer-reviewers at Cultural Analytics, for their helpful feedback.
Ch. 5: 69, 72; Ch. 6: 91; Ch. 10 148; Ch 13: 177, 180; Ch. 14: 191; Ch. 15: 210 (3 times), 211, 212; Ch. 17: 230 (3 times), 231 (3 times), 232, 242 (twice); Ch. 18: 245 (4 times), 249 (twice), 250; Ch. 21: 285; Notes and Index: 9 times.
Running listings: https://socialblade.com/tiktok/top/50/most-followers;
For discussions of these pranks, see Turkey Tom.
See acknowledgments.
One more creator with no content meeting the criteria was removed at this phase
https://web.archive.org/web/20230327030031/http://socialblade.com/youtube/top/100
https://www.tiktok.com/@zachking/video/7213761915842202926; https://www.tiktok.com/@zachking/video/6768504823336815877
During labeling, this genre was called the “Hypnotic Process Video,” as reflected in the codebook; in this essay, I alter the term to avoid the awkward acronym “HPV.”
https://www.tiktok.com/@daviddobrik/video/6929292581364894981
https://www.tiktok.com/@skyandtami/video/6809105779782585605
https://www.youtube.com/watch?v=LeYsRMZFUq0; https://www.youtube.com/watch?v=krsBRQbOPQ4
https://www.tiktok.com/@itsnastynaz/video/7090222333155134763
https://www.tiktok.com/@topperguild/video/7154181118055697710
https://www.tiktok.com/@thekiryalife/video/7173240706234993921